Trial Group,如同他的名字,是数据分组的意思。
我们执行数据分组无非就是一个目的,把具有一个或者多个相同特征的试次放到一起来批量执行特定的处理。
举个最简单的🌰来说,我使用了边界触发范式来进行一项实验,那么我的数据里面会有很多不会发生边界触发的填充试次。对于这样的试次,我们通常叫他们“Filler”。在数据处理的时候,我是不需要分析这些Filler的试次的。于是我们可以在DV中借由Trial Grouping功能将标注为Filler的试次找出来,统一删掉。
有或者,我们将显示内容相同的试次找出来,给他们应用相同的兴趣区设置,也会用到Trial Grouping的功能。操作层面则是将所有的试次依据呈现的刺激内容进行分组,分好组后我们就可以设置兴趣区了。
言归正传,先来看一看我们执行Trial Grouping之前,数据是如何分组的。
首先,我导入了两条数据,采集的时候分别命名为“br.edf”和“dm.edf”。导入后数据结构如下:
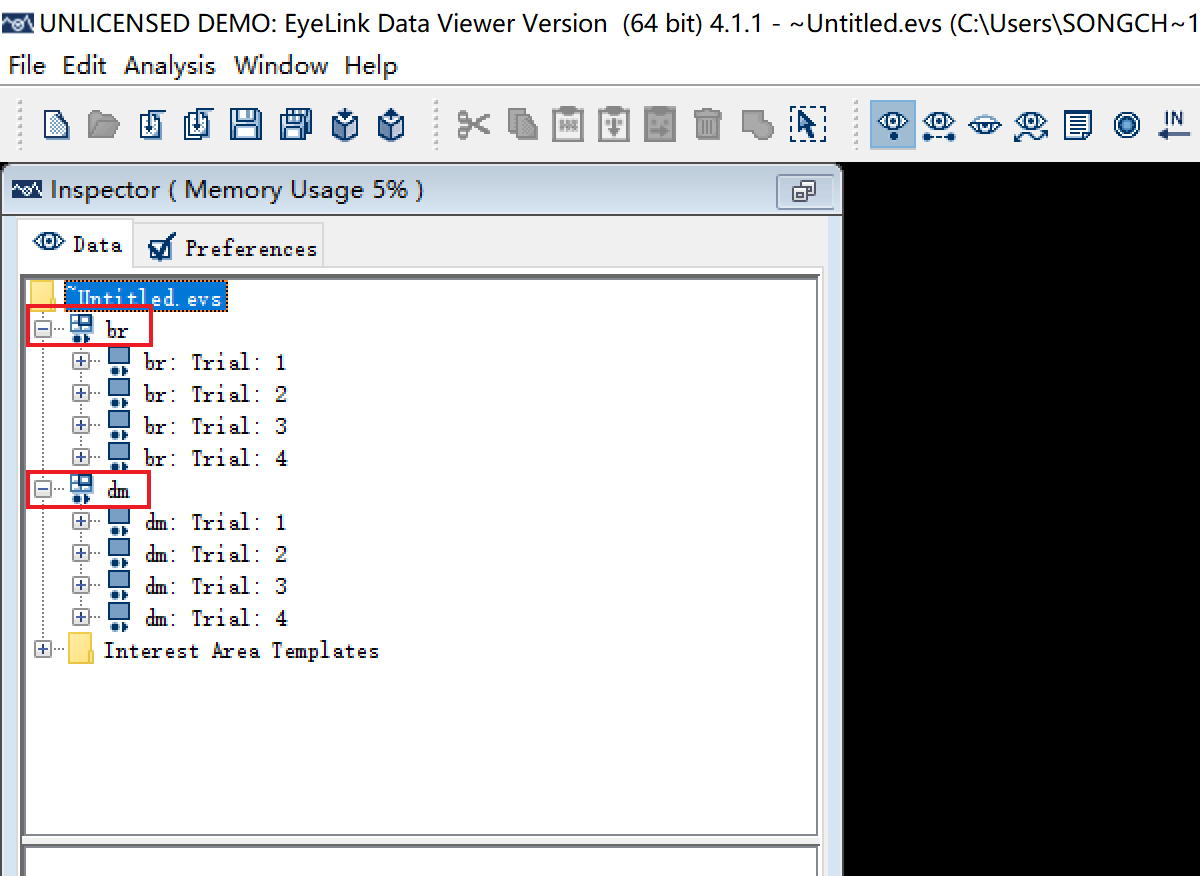
我们可以看到数据的树形结构是这样的:
此时的分组依据为默认的“Recording Session”,即我们采集数据时的一个个数据文件。
在菜单栏中依次点击“Edit - Trial Grouping”。

然后我们就可以看到Trial Grouping的窗口了。
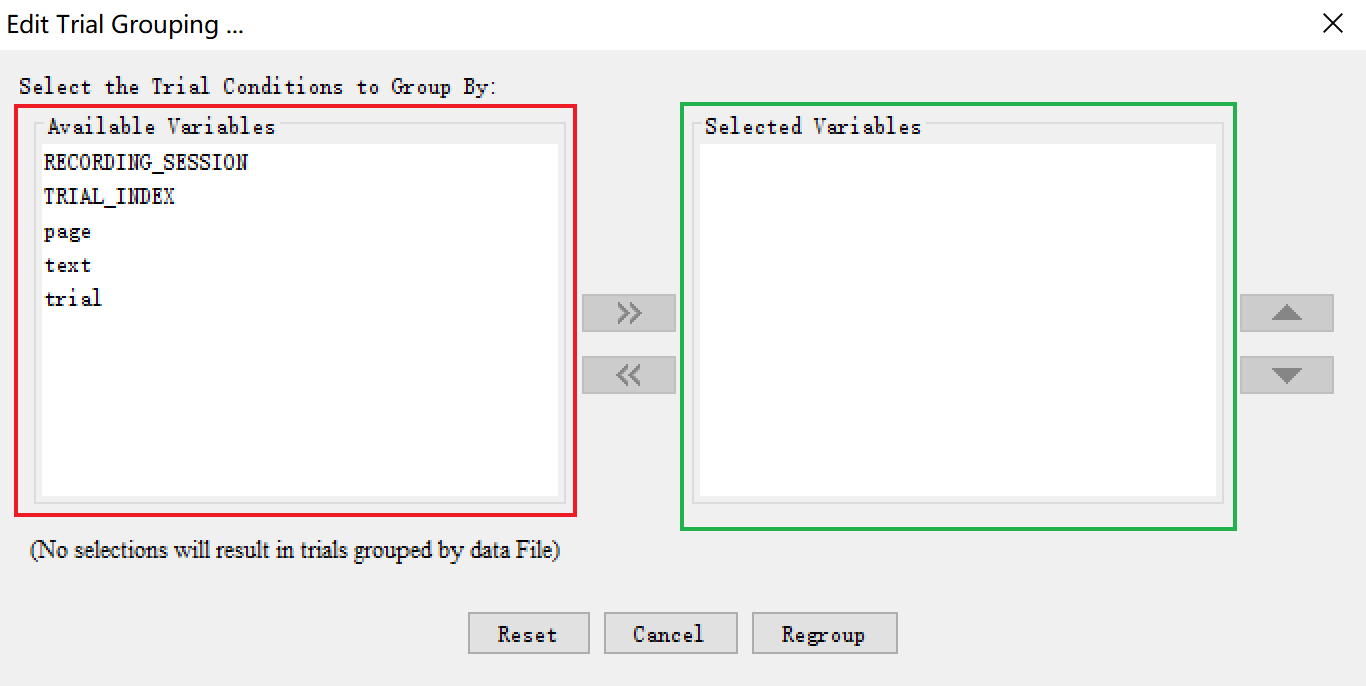
- 左侧标记为红色的区域是可以用来分组的条目;
- 右侧标记为绿色的区域是已经被选中作为分组依据的条目。
左侧红框中可用的分组条目主要有两个来源:
- 默认的Recording Session和Trial Index:
- Recording Session指我们在记录眼动数据时输入的
.edf文件的名字; - Trial Index指试次的运行顺序;
- Recording Session指我们在记录眼动数据时输入的
- Datasource中的Column的名字,即我们在Datasource中创建了多少列就会增加多少个分组的依据条目。下图即为在EB中编程所设计的Datasource,您可以注意三个Column的名字和Trial Grouping中可用的分组依据的关系。

再举个🌰,前面在编写Datasource的时候,Charlie曾经强调一定要给每个试次做一个Trial_ID的编号。大多数情况下,不同被试,相同Trial_ID的试次,呈现的是完全相同的刺激内容。因此我们可以以Trial_ID为分组依据进行Trial_Grouping,来针对性地对不同刺激内容绘制兴趣区。
具体如何来设置兴趣区我们会在后面的章节中讲述,这里我们暂时使用第一个Filler的🌰来演示Trial Grouping的具体操作。
下面我准备了一个边界触发范式的Datasource,为了简化,我只准备了4个试次。
| Trial_ID | Type | Page | Text |
|---|---|---|---|
| 1 | Seem | Buck | Buck did not… |
| 2 | Control | House | The house was… |
| 3 | Unrelated | They | They came and… |
| 4 | Filler | Among | Among the terriers… |
可以看到“Type”列中分别标记了四个试次分别为:
- Seem - 字形预示,预示字和目标字在字形上相似;
- Sound - 控制试次,直接呈现目标字;
- Unrelated - 无关预示,预示字和目标字完全不同;
- Filler - 填充试次,为了凑数量的试次,和实验内容无关。
在处理边界出发范式的数据的时候,我们通常会直接删除掉Filler的试次,减少没必要的工作。
打开Trial Grouping窗口,选择依据Type进行分组。您可以直接在窗口中双击Type,也可以选中Type后点击窗口中心指向右边的小箭头>>。
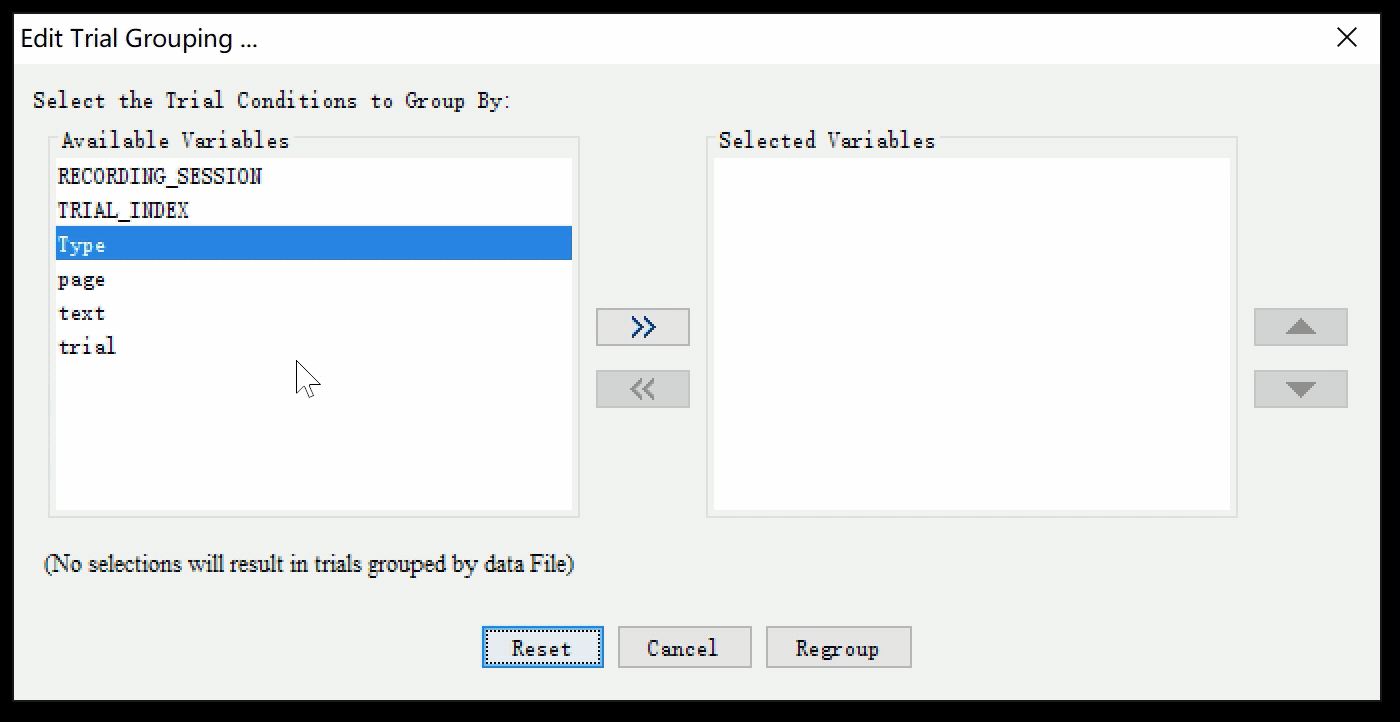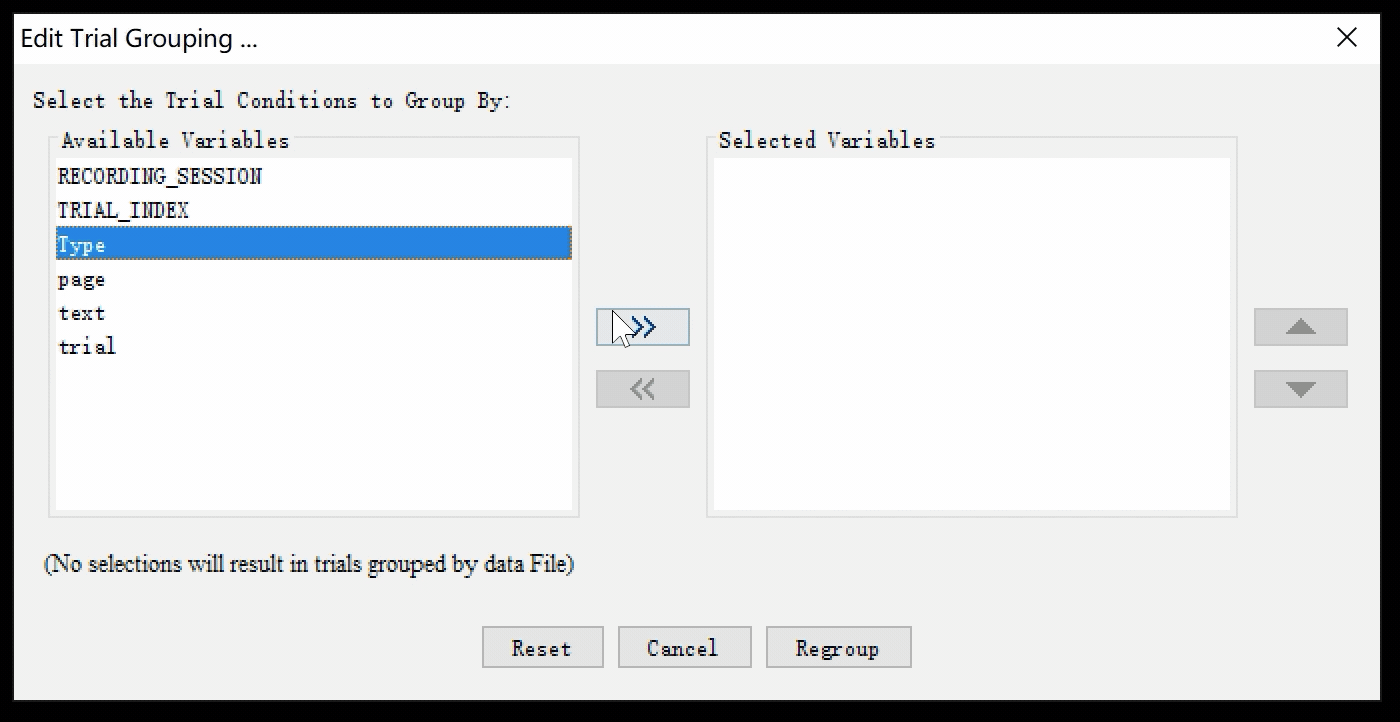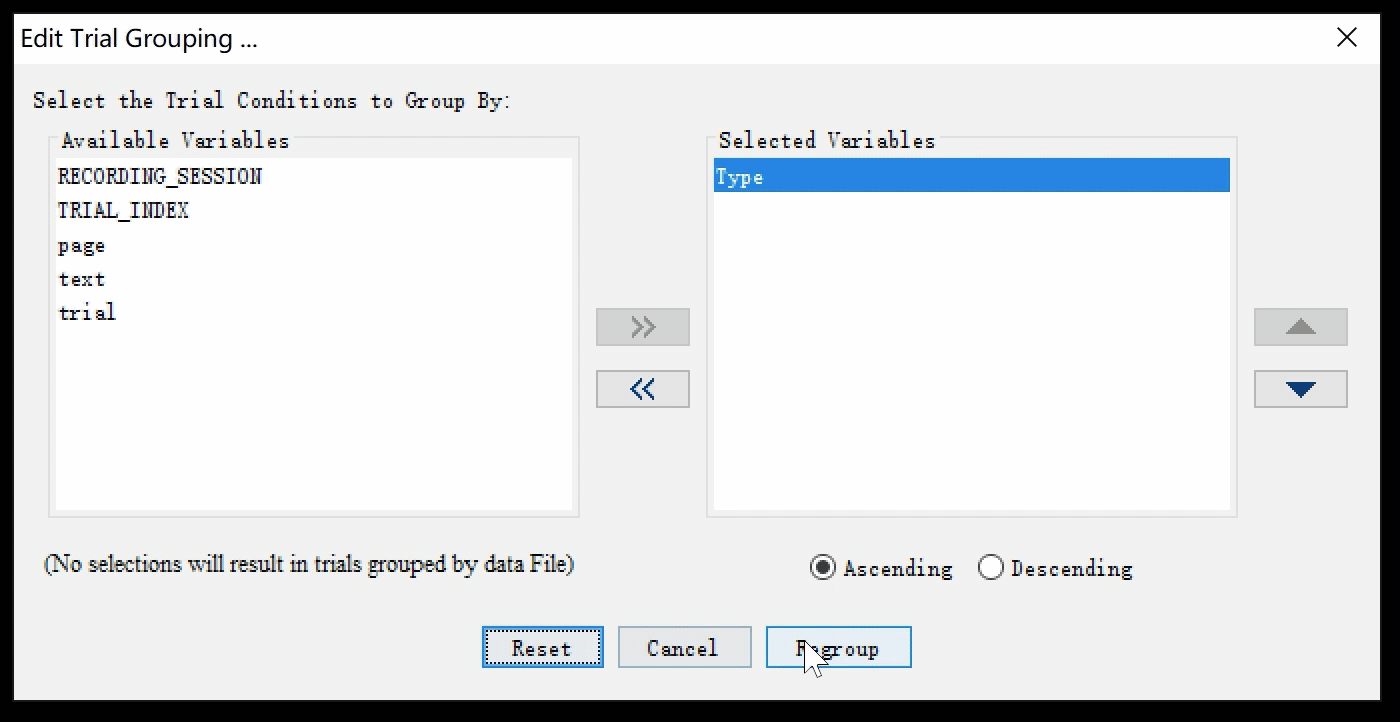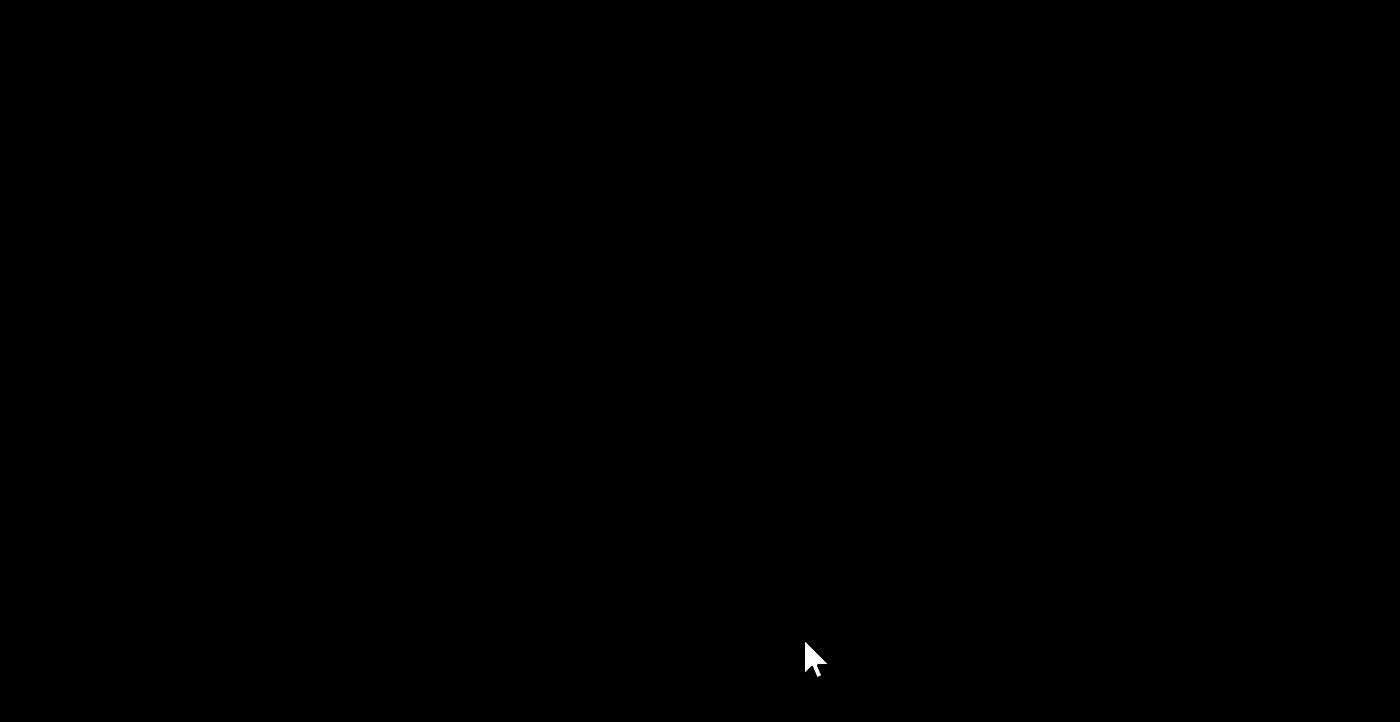
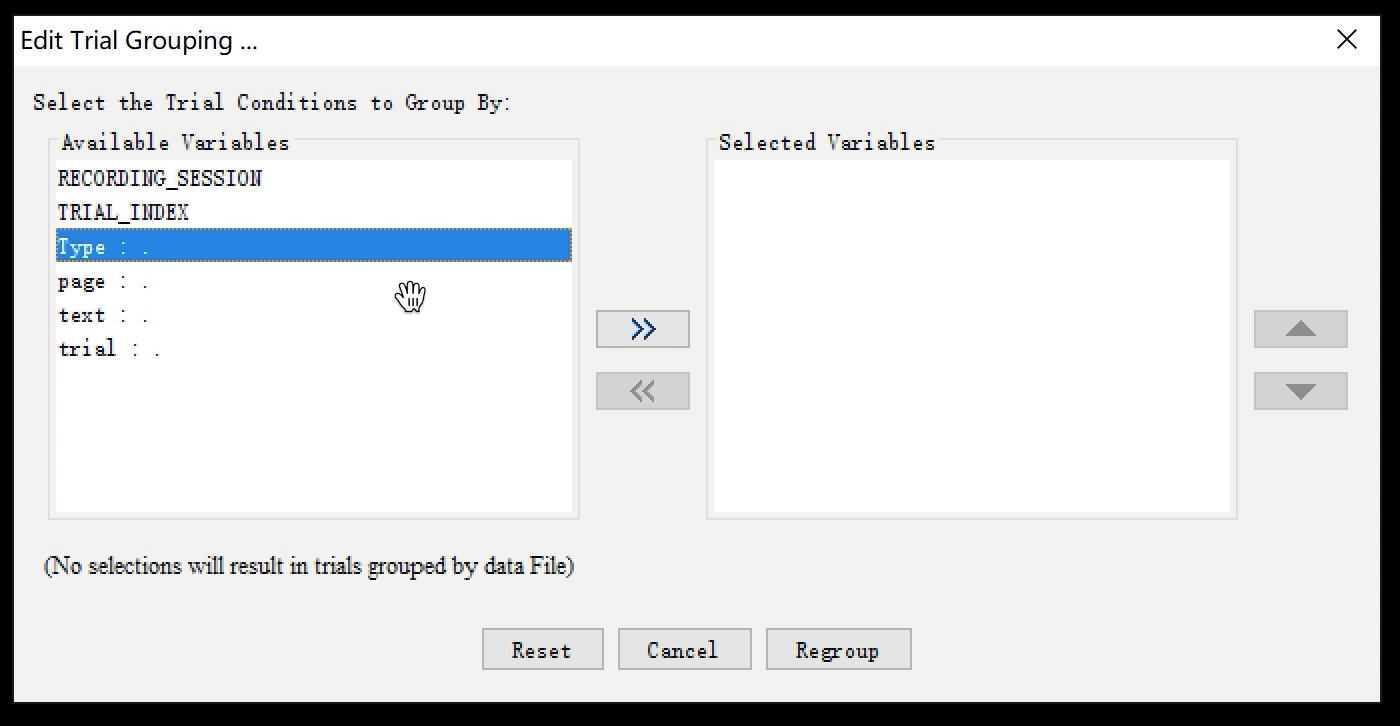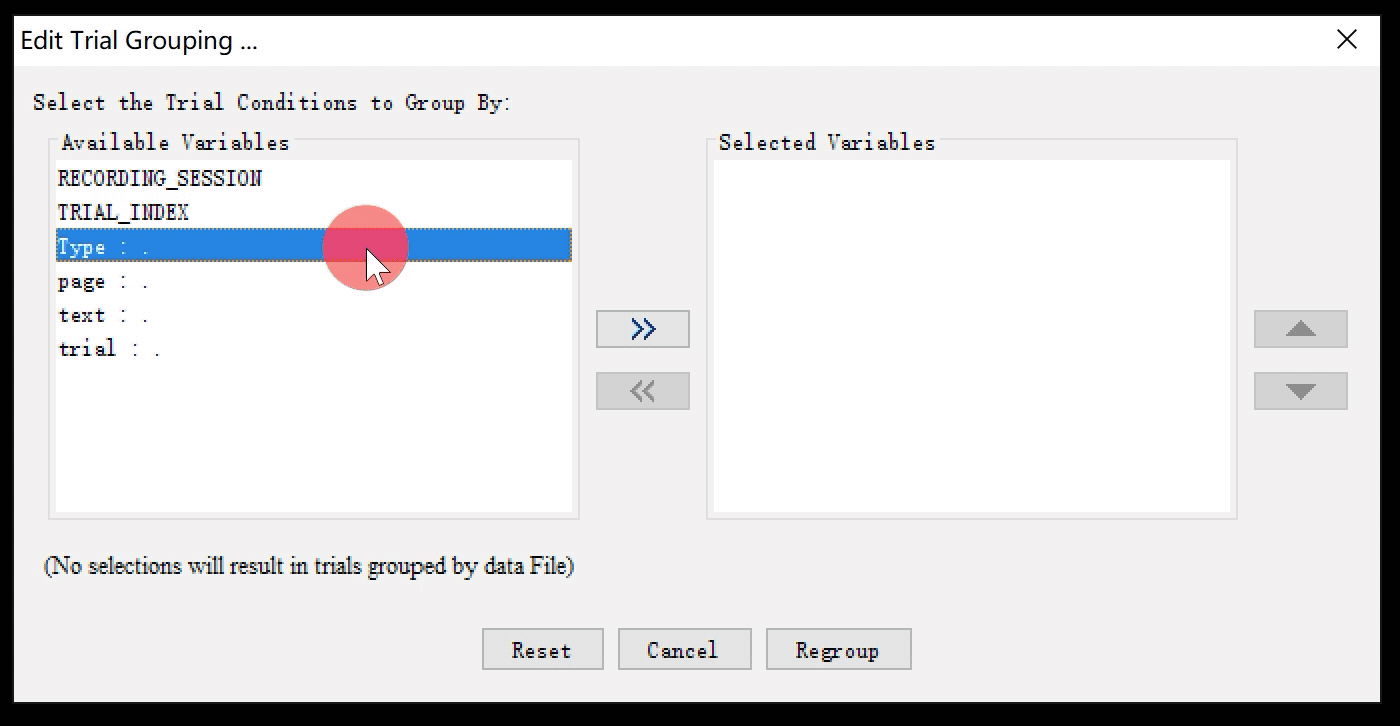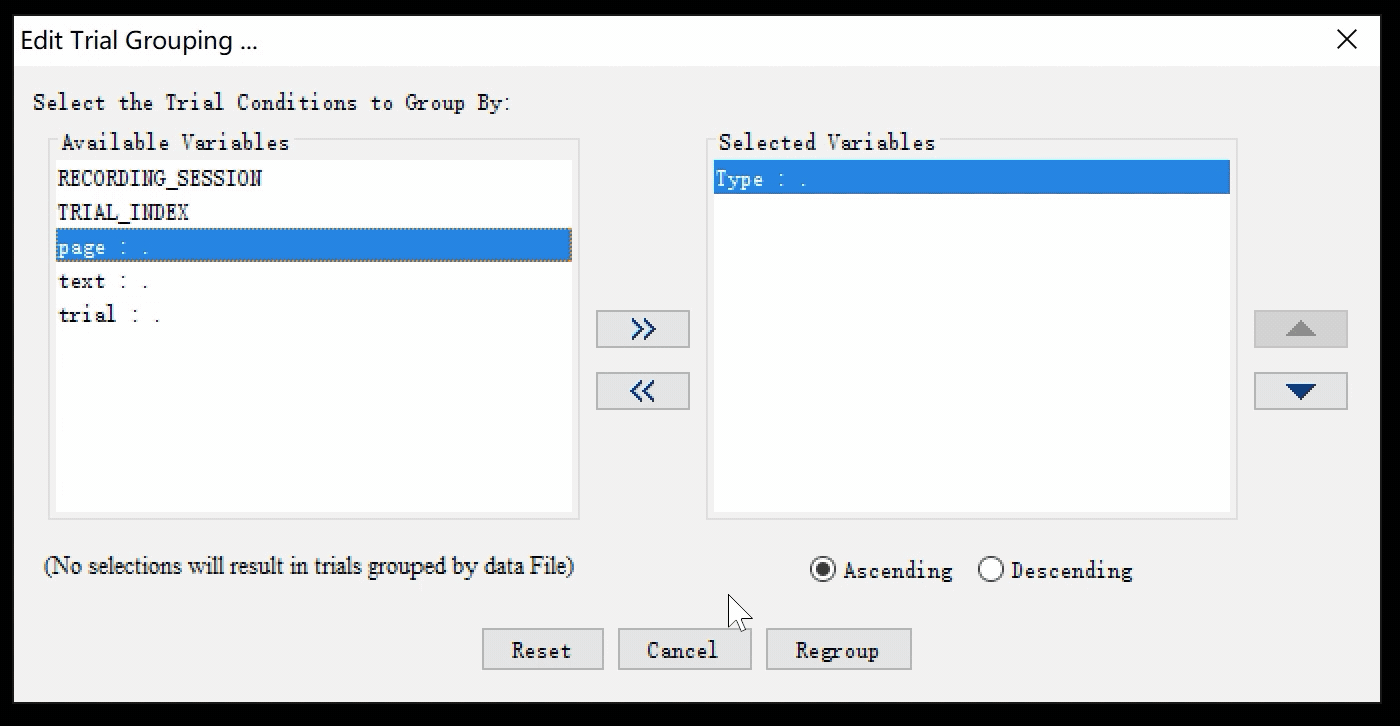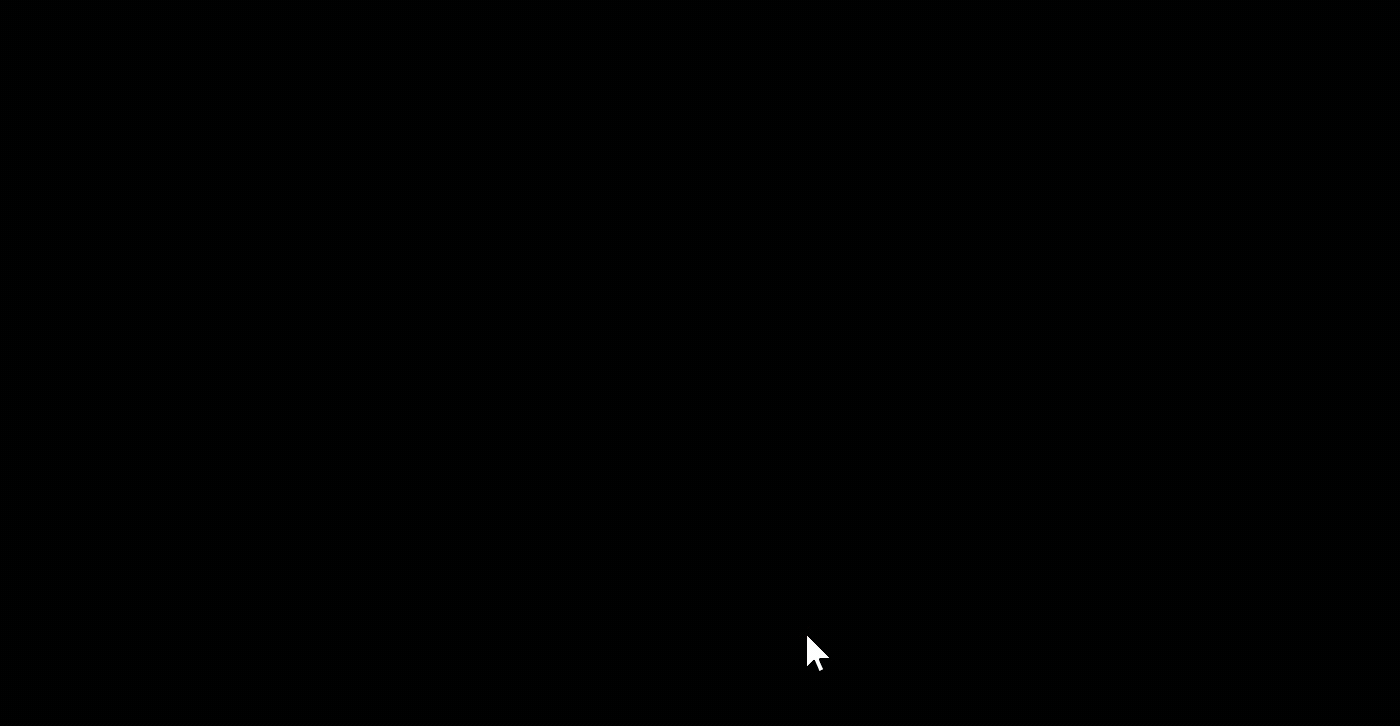
这时我们可以看到在Data Inspector中,数据分组的方式已经发生了改变:
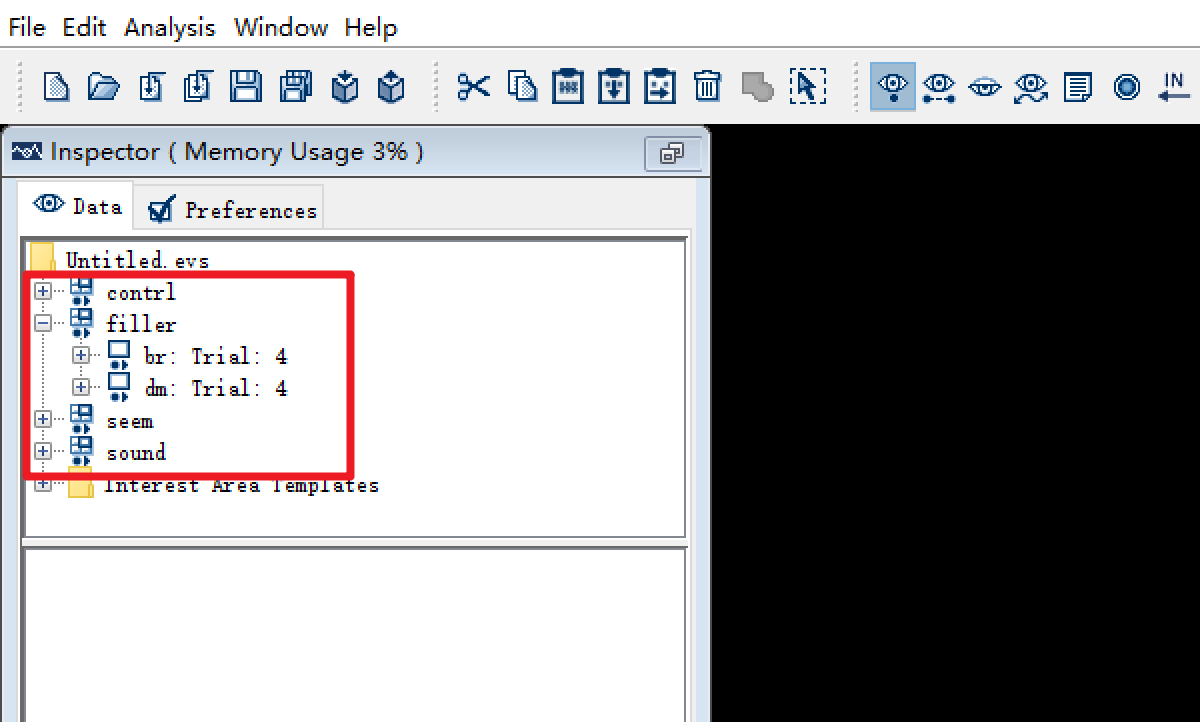
所有属性为“Filler”的试次已经被归到一起了,让我们来愉快地删除它。
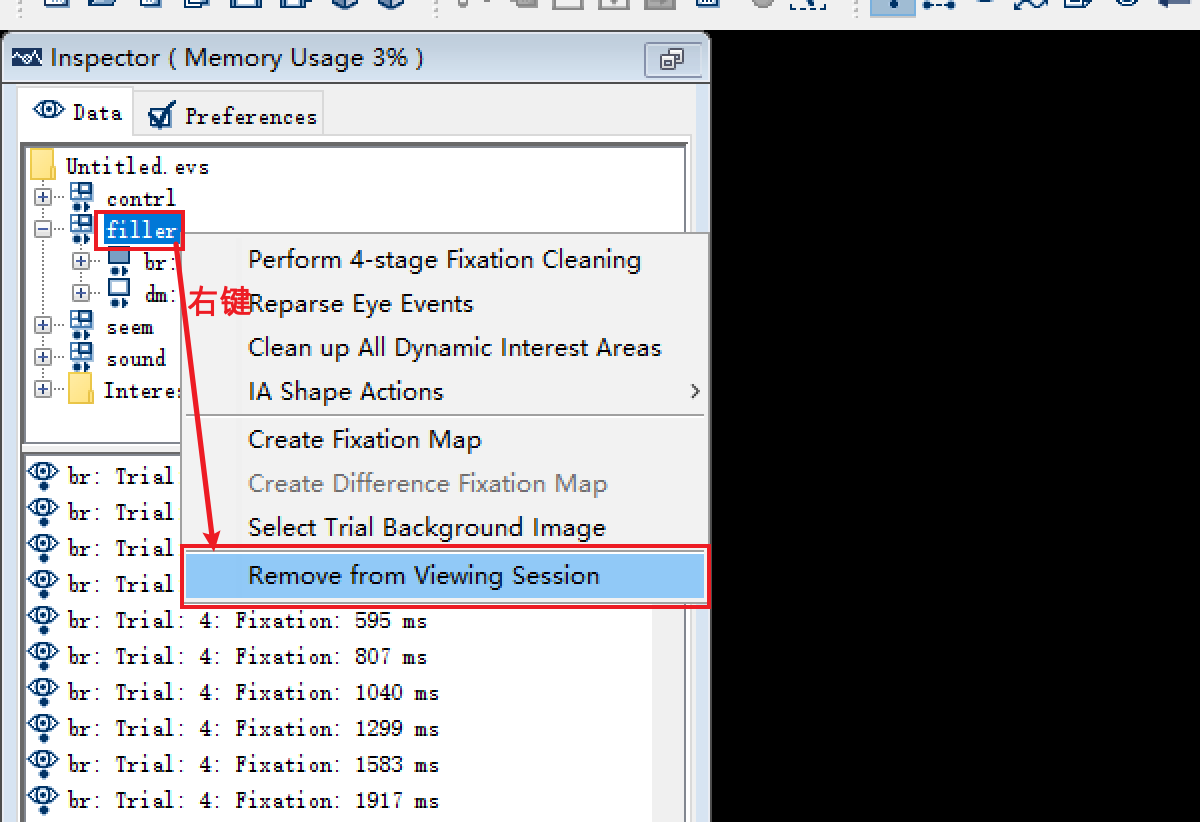
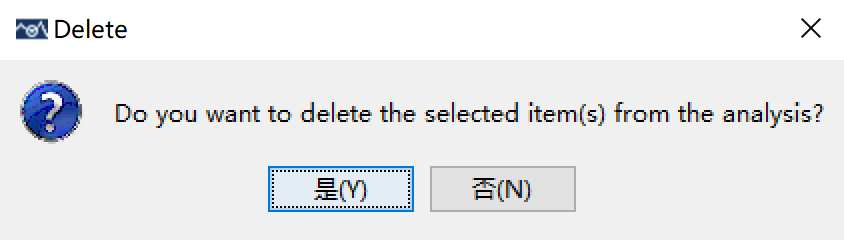
在随后的提示窗口中愉快地点击“是(Y)”即可。
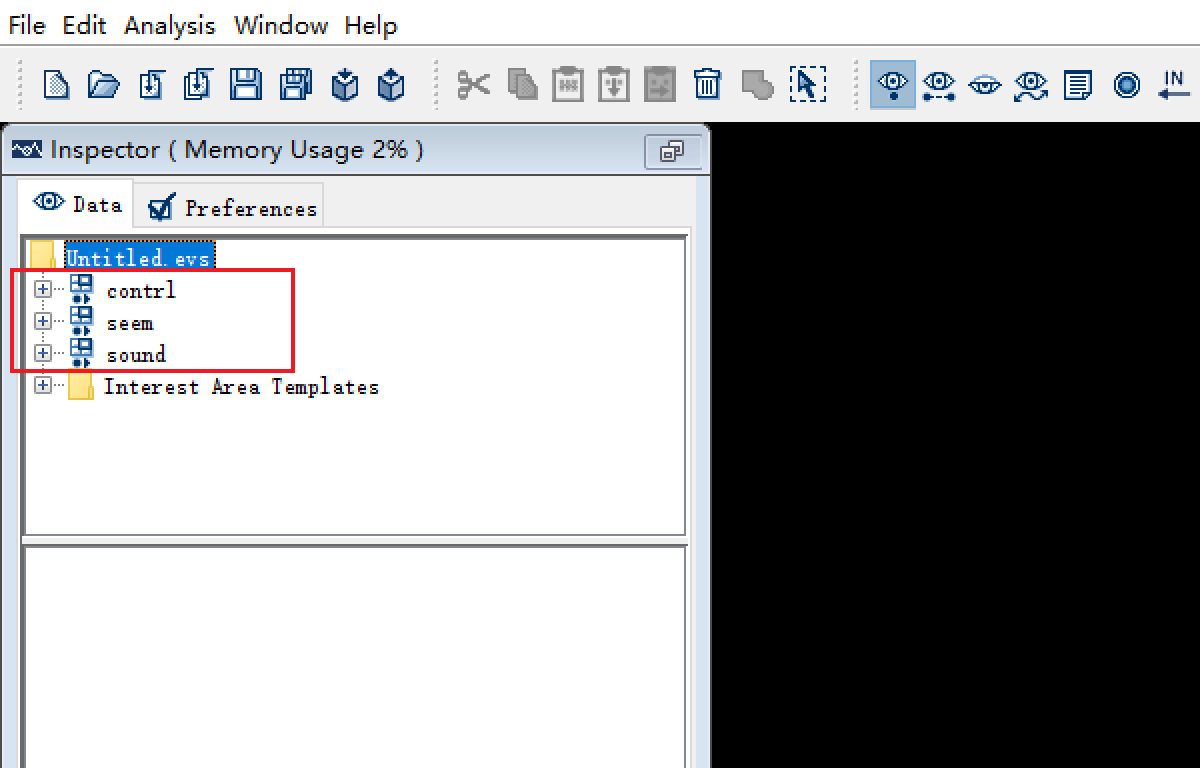
回来看Inspector中的数据,已经删除掉啦!
是否需要Trial Grouping这一步,取决于我们对数据处理的需求。有些条件下,您可能完全不需要进行这一步。
以上。