1. 为什么要设置随机
通过随机或者拉丁方等方法,可以避免因试次运行顺序引入的不可控的变量。设置随机的理论可以很简单,也可以非常复杂。这里不是实验设计的教程,因此这部分暂且略过。
我们这里使用一个比较简单的方法——让所有试次的出现顺序随机。
关于拉丁方随机的内容,您可以参照这篇文章»>传送门«<。
2. 设置随机
在Datasource中打开Randomization Setting。
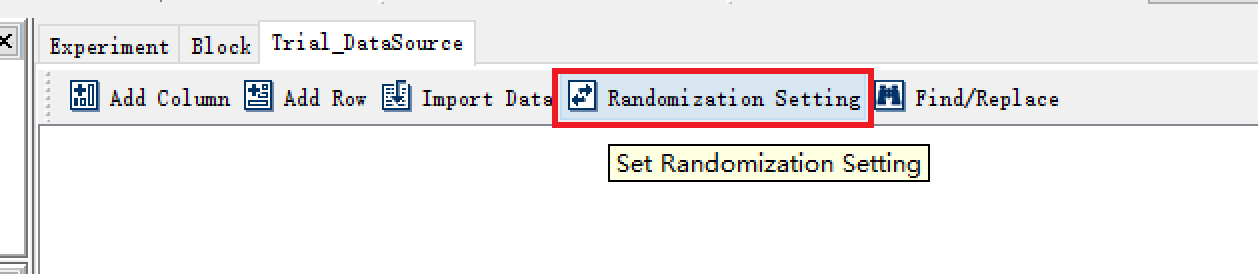
跳出如下图所示的随机设置窗口,具体每个部分的含义我们放到最后来解释,我们先跟随具体的需求一步一步来操作。
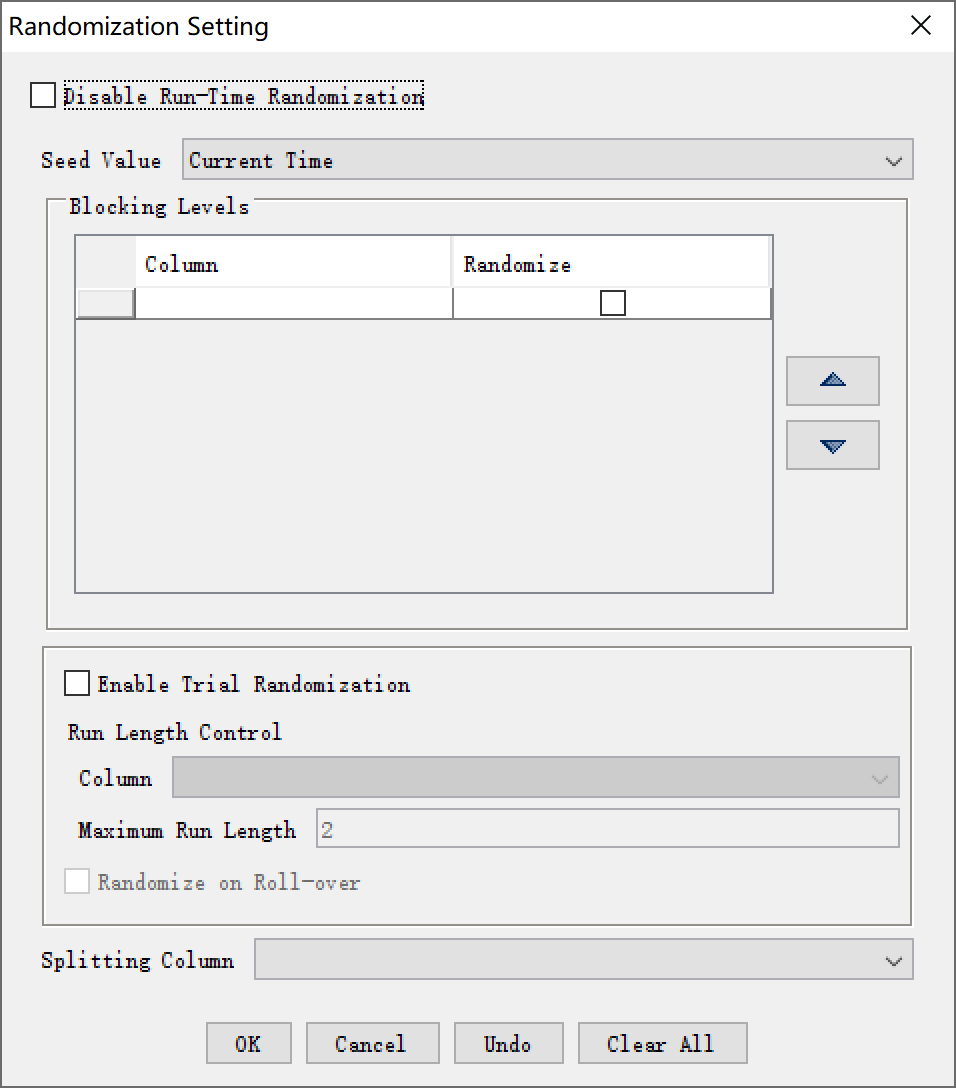
2.1 设置试次随机
试次随机基本上可以说是最实用的随机方法了,设置的方法也非常简单,只勾选一个Check Box即可。
以本实验为例,一共4个试次。
-
如果不
Enable Trial Randomization的话,每个被试来做实验的时候都是从第1个试次到第4个试次依次进行的。 -
如果
Enable Trial Randomization的话,那么每次运行试验的时候,4篇文章的出现顺序将会被随机打乱。
2.2 设置分割Block
分割Block的时候,通常是以下两种情况:
-
在正式实验之前,希望添加一个练习的部分,让被试熟悉实验流程,我们称之为练习的Block;
-
当试验整体时间过长的时候,我们可以通过一些设置,将实验分割成多个Block,让被试在每个Block之间得以休息。
2.2.1 分割练习Block
此处我们忽略实验设计的合理性,将仅有的4篇文章分1篇出来用作练习实验。我们应该如何设置呢?
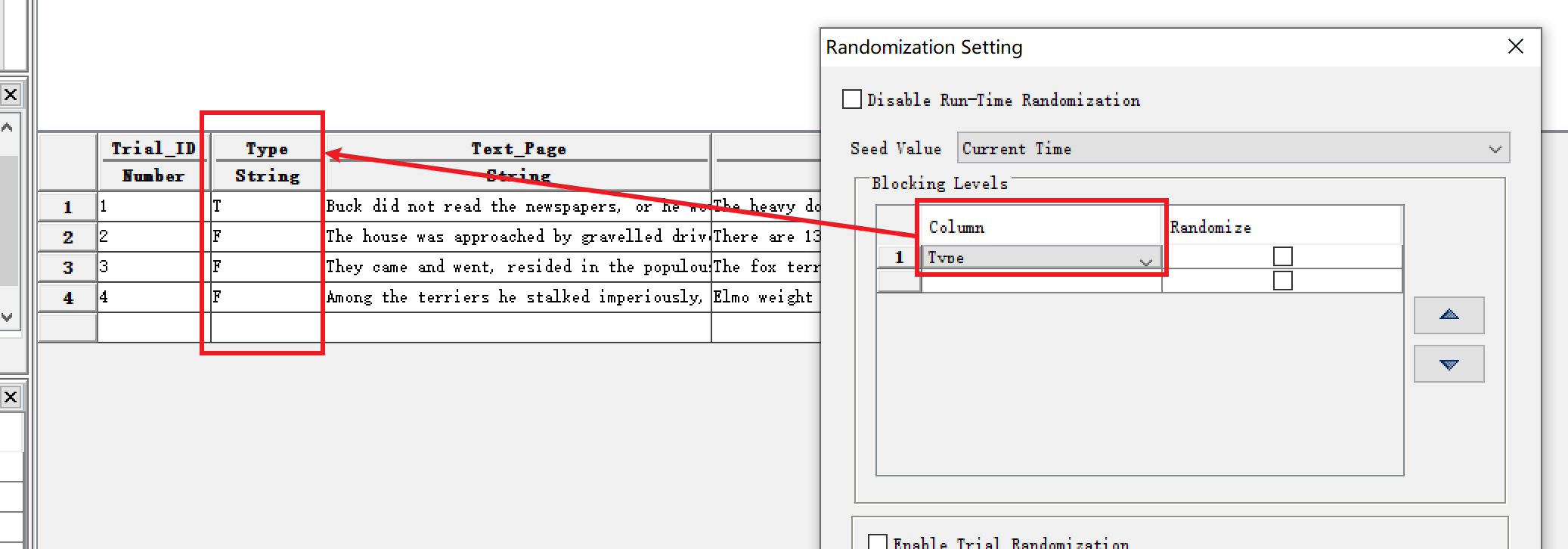
首先在Datasource中新建一个Column用来标记哪些试次是练习部分,哪些试次是正式实验部分:

如上图所示,我新建了一个名为“Type”的Column,其中值为“T”的试次是练习部分(Training Part),值为“F”的部分为正式实验部分(Formal Part)。
接下来我们要进行属性设置,稍微有些复杂。拆开来看,我们需要做三件事:
设置Block层的循环次数 -> 设置每个Block执行多少个Trial -> 设置Datasource分割
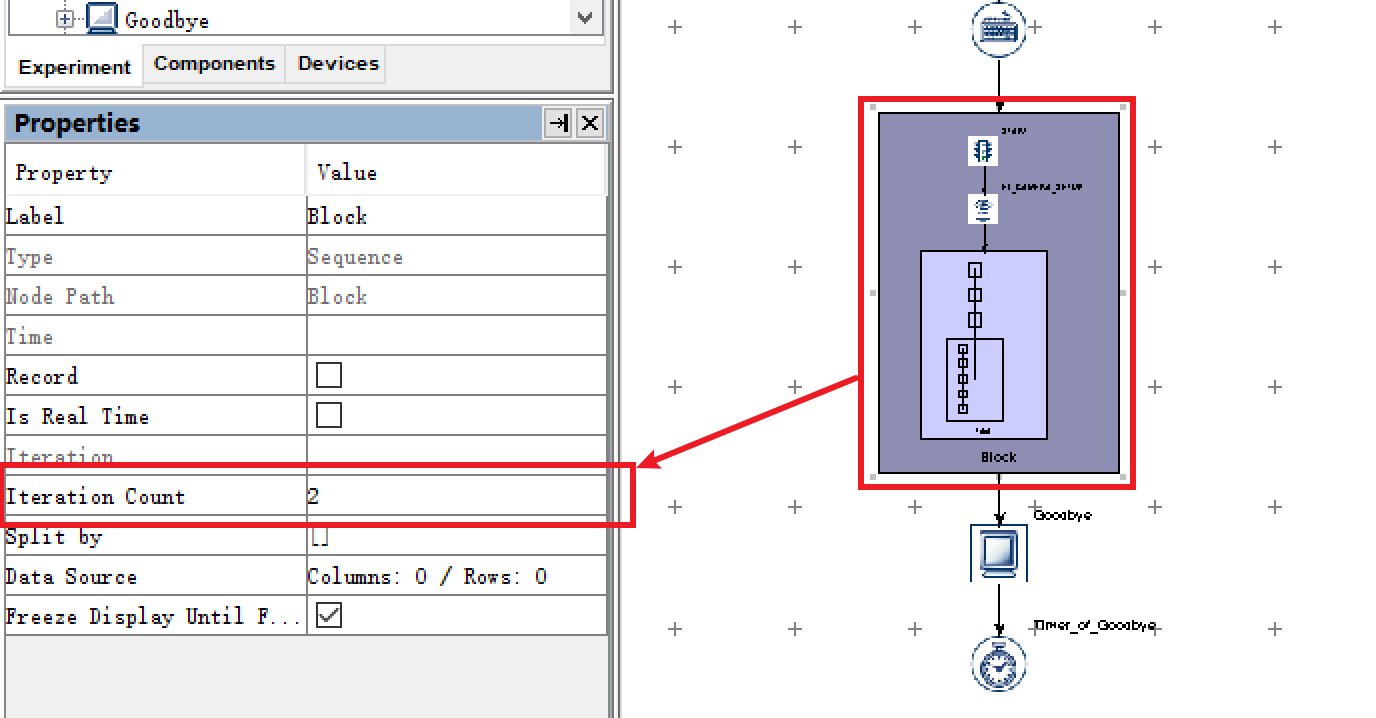
- 首先,设置
Block层的循环次数。
练习部分是1个Block,正式实验部分是1个Block,一共两个Block。那么就是让
Block层执行2次,第一次执行练习的1个试次,第二次执行正式实验的3个试次。
Sequence控件有一个属性叫做Iteration Count,即重复次数。因此我们将Block层的Iteration属性设置为“2”。
- 设置每个Block执行多少个Trial
选中
Trial层,我们可以看到Iteration Count和Split by两个属性。
Iteration Count目前的值为4,其值默认与Datasource中的数据行数相同。即重复运行4次Trial层,每次运行Datasource中的1行。
Split by属性默认是空,意为一次性执行完全部4个Trial。我们的需求是将4个Trial分成两次执行,因此将Split by属性设置为“[1, 3]”。
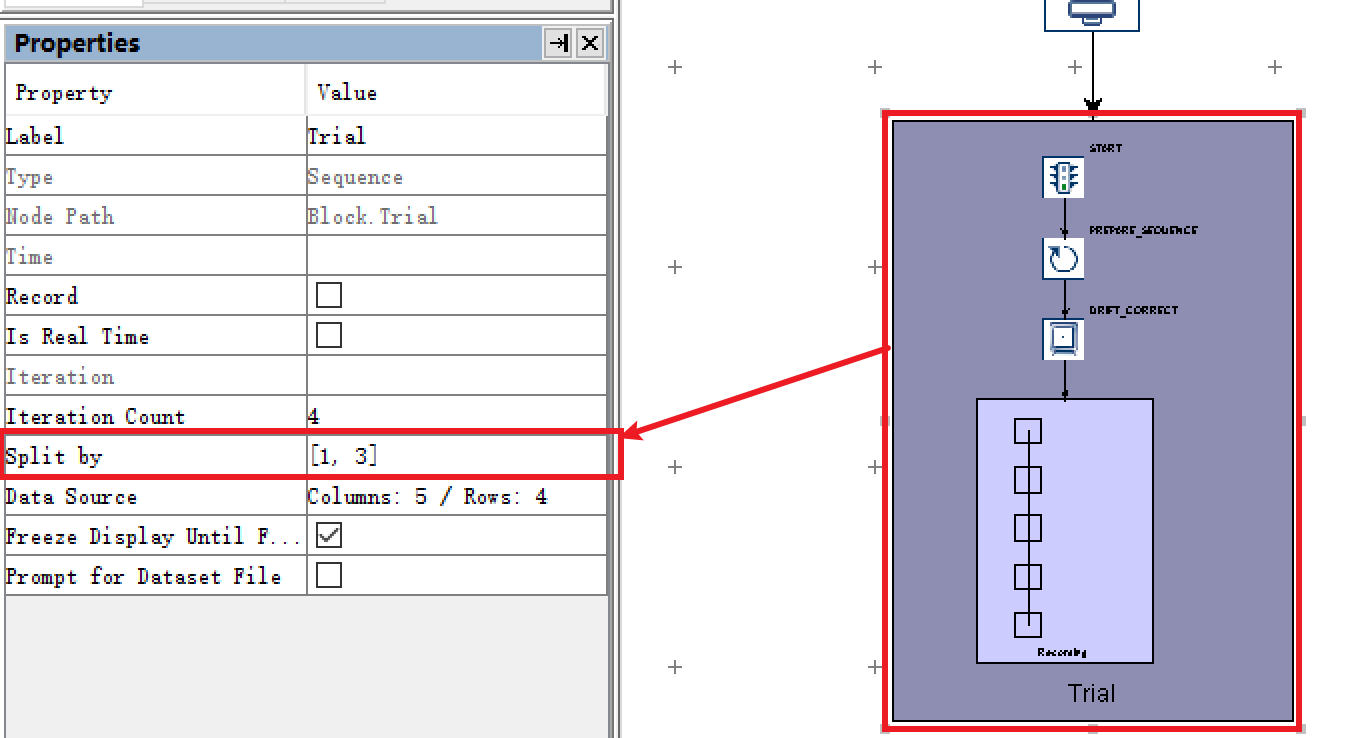
⚠️注意⚠️:“[1, 3]”中的逗号必须是英文逗号,不能是中文。
- 设置
Datasource分割
在
Datasource中打开Randomization Setting,设置Block Levels为“Type”,注意后面的Randomize不要勾选。
结合前面对于
Block层的Iteration Count和Trial 层的Split by,我们已经成功将实验分割成了1个试次的练习Block和3个试次的正式Block。
2.2.2 分割正式实验的Block
问题继续,如果正是实验部分的时间非常长,试次非常多,那么我们应该如何操作才能让被试在中间休息呢?
忽略实验设计的合理性,我们现在将正是实验部分的3个Trial拆分成3个Block。
- 修改
Block层的执行次数
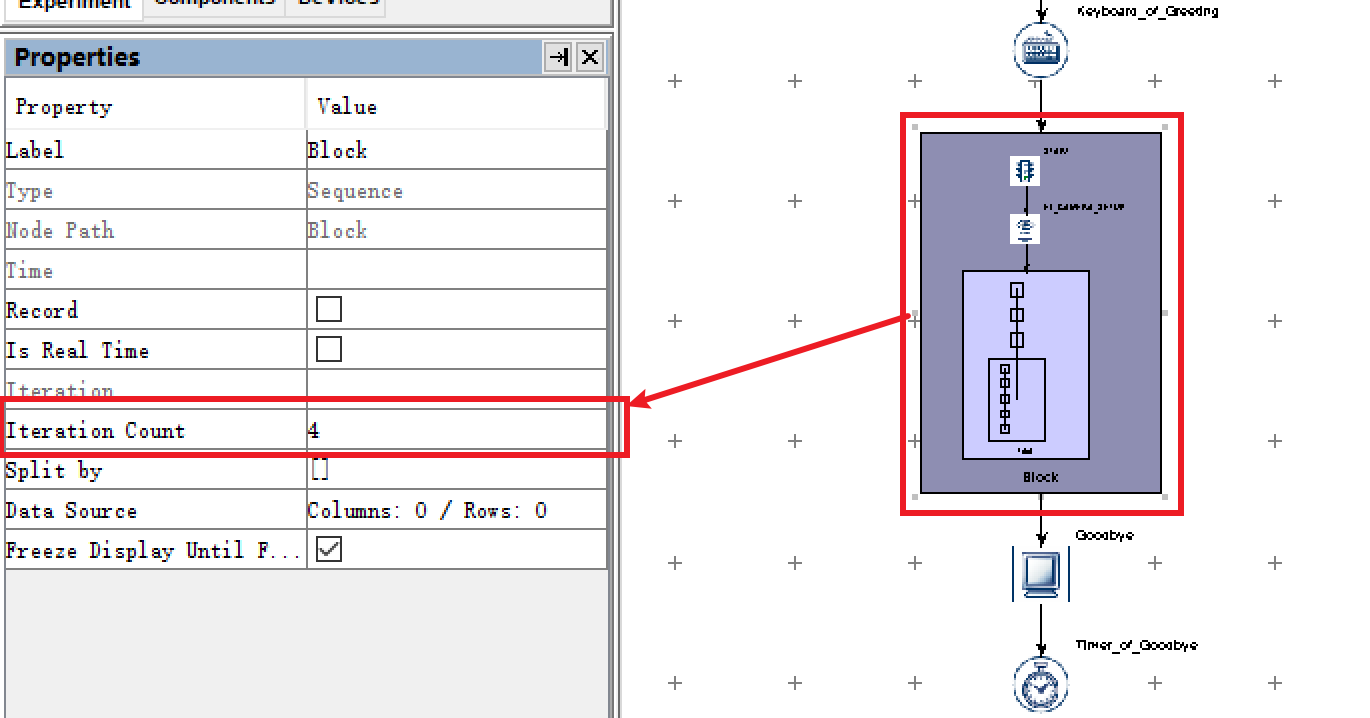
因为将正是实验的1个Block拆分成了3个Block,算上练习Block的话,总的Block数变成了4个。因此,首先修改
Block层的Iteration Count为“4”。
- 修改
Trial层的Split by属性。
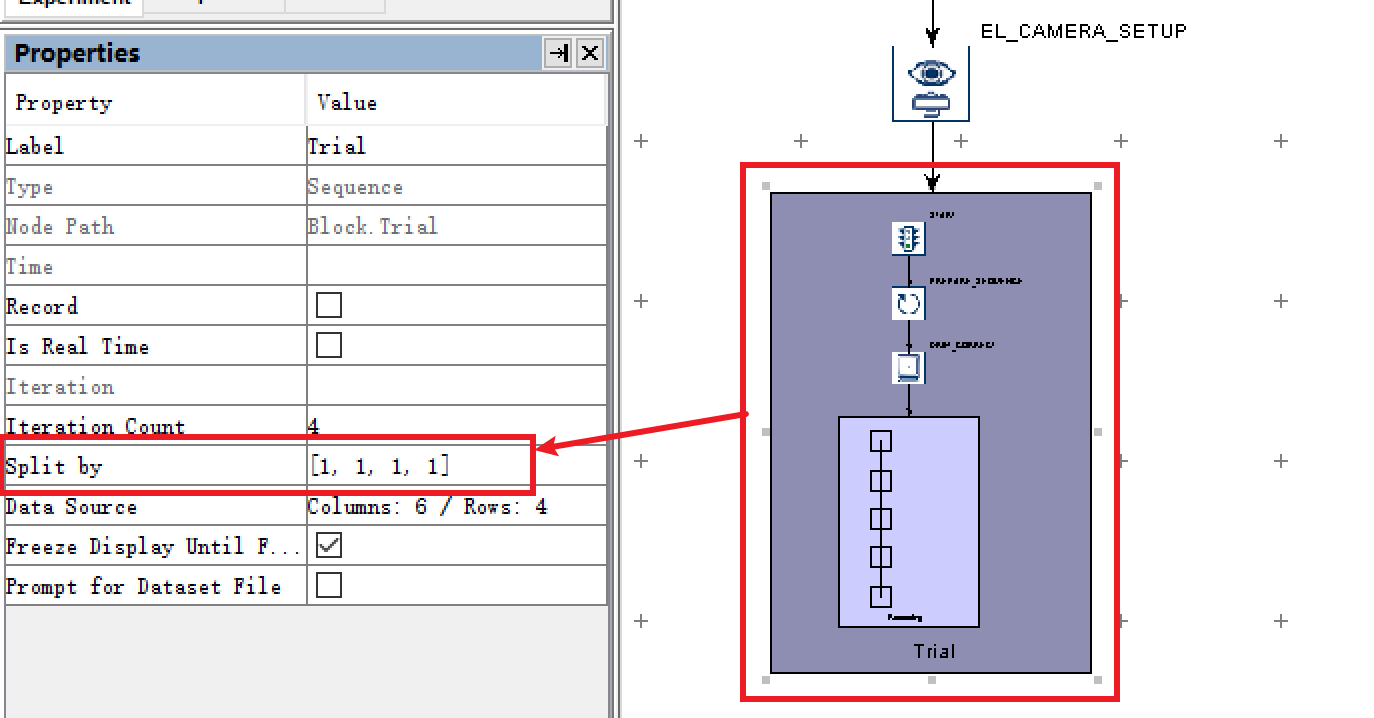
由于Block数量的变化,每个Block执行的Trial数量也有变化,根据实际情况进行分割,即4个Block,各分别执行1个Trial。因此修改
Trial层的Split by属性为“[1, 1, 1, 1]”。
这部分操作的逻辑其实是这样的:
在Randomization Setting中的Block Level设置了Type Column,则运行的时候就会先寻找Type Column里面第一行的值,即T。
执行完T的部分会寻找第二种类型,即F。但是由于Split by的限制,每次只执行1个Trial,共执行三次。就是这样讲3个Trial划分成了3个Block。
由于Randomization Setting设置了Enable Trial Randomization,所以F部分的执行顺序是随机的。相当于把所有F部分一起先做随机,再分批次执行。
2.3 设置分割实验
继续深入,有些时候我们还会碰到这样的一个需求:
我的实验设计会将我的实验分成两种情况,分别给两组不同的人做。但是实验结构是相同的,只是内容上有差异,该如何处理呢?
方法其实很简单,我们将所有的素材全部放入Datsource中,新建一个命名为Group的Column来标记两组素材。当然,根据情况也可以更多组。
- 修改
Datasource
新建一个命名为
Group的Column来标记两组素材。点击
Add Rows,根据情况添加行数,将Datasource粘贴进来。此处我直接复制了上面的Datasource。将两组
Datasource的Group值进行修改,我这里分别赋值“A”和“B”。

- 修改
Randomization Setting设置
这部分我们使用
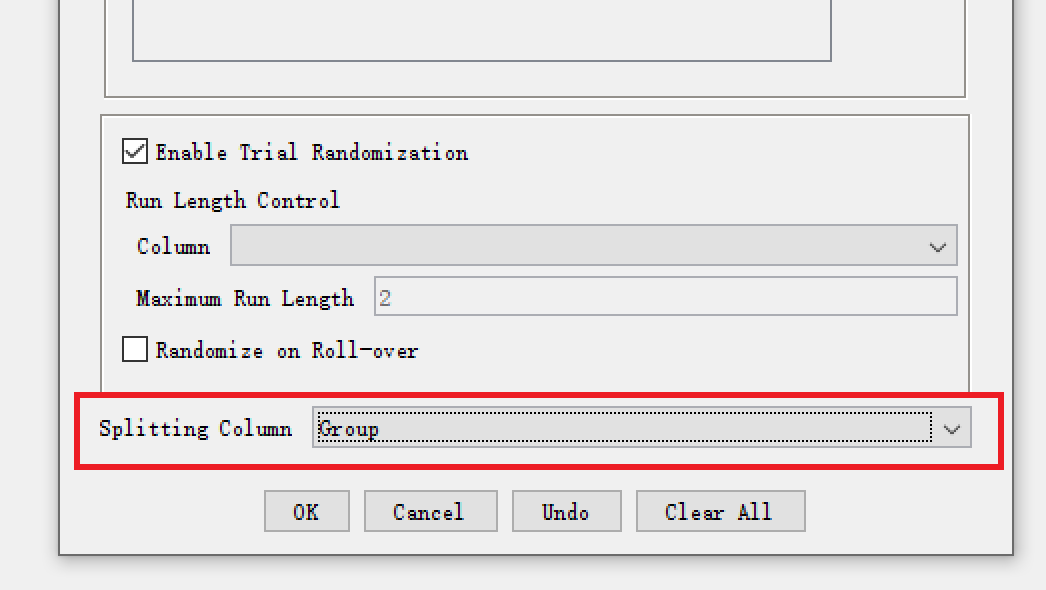
Randomization Setting中的Splitting Column功能。如下图所示,设置
Splitting Column功能为“Group”。则系统会自动识别“Group”这个Column里面的内容,将其分割为不同的实验。
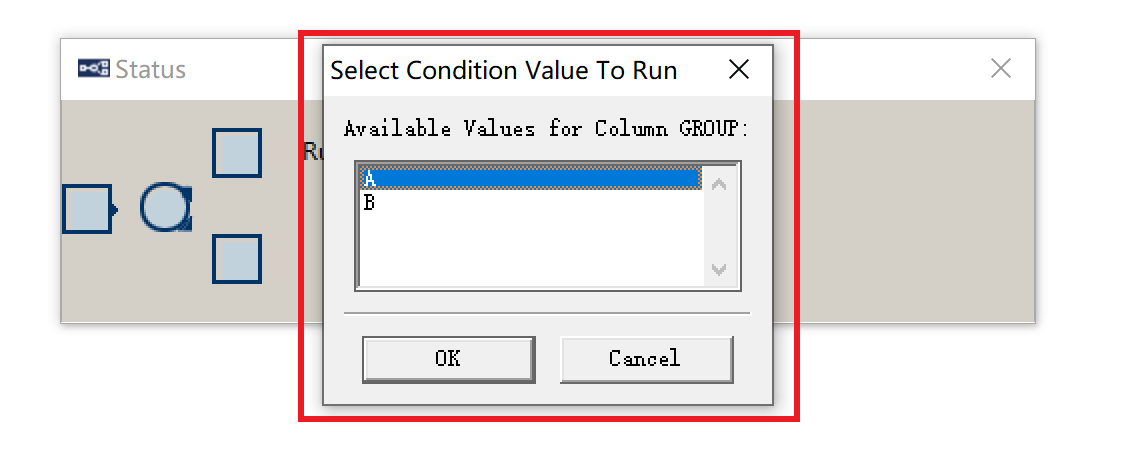
在我们运行试验的时候,就回出现下图的提示窗口,让我们选择运行
Datasource中的哪部分。
Test Run一下试试效果吧!

以上。