绘制兴趣区这一步,可以在编写程序的时候准备好,也可以在处理实验数据的时候再进行。
但Charlie要说的是:“永远把准备做在前面”。
阅读任务中,所谓绘制兴趣区,其实是根据需要进行分词。例如:
An apple a day, keeps doctor away.
在英文中,分词是一件非常简单的事情。一个一个单词已经摆在这里了,以词为单位的分词显而易见。
这件事在中文上面就变得复杂一些。
天天玩苹果手机,拿不到博士学位。
这句话该如何分词呢?在不同研究中,由于研究目目的的不同,会有不同的分词方式。Charlie在这里举一个最基础的例子:
|天天|玩|苹果|手机,|拿|不到|博士|学位。|
在进行一句话的兴趣区设置时,我们需要绘制多达8个兴趣区,而这只是短短的一小句话。
如果每个试次都是一大段话呢?抑或我们有几十个试次呢?工作量会大到无法想象。
所以我们需要EB软件替我们完成这个恼人且枯燥的工作。
EB又一个自动划分兴趣区的功能——Auto Word Segment。
我们需要人为地指定某个特殊的字符为分词符,并提前讲分词符嵌入到文本中需要分割为兴趣区的地方。以中文为例,我定义“#”为分词符,那么对于前面的例子,我需要讲Datasource中的文本内容更改为:
天天#玩#苹果#手机,#拿#不到#博士#学位。
EB软件会自动地识别“#”,并将两个相邻“#”之前的文字分割为一个兴趣区。在此同时,EB会将文本中的“#”删除掉,使其不会显示出来,也不会有空位。
分词文字 - 英文、俄文、阿拉伯文等
此类文字的特点是词与词之间有空格分开,天然形成分词。因此我们只需要指定空格为分词符即可完成兴趣区分词。同时注意不要删除分词符,否则所有单词都会连到一起。
Step 1: 开启Auto Word Segment功能
在工具栏中点击Preference,在左侧的树状结构中依次点击“Preference - Screen - Built-in Interest Area Preference - Word Segment”,找到Word Segment。
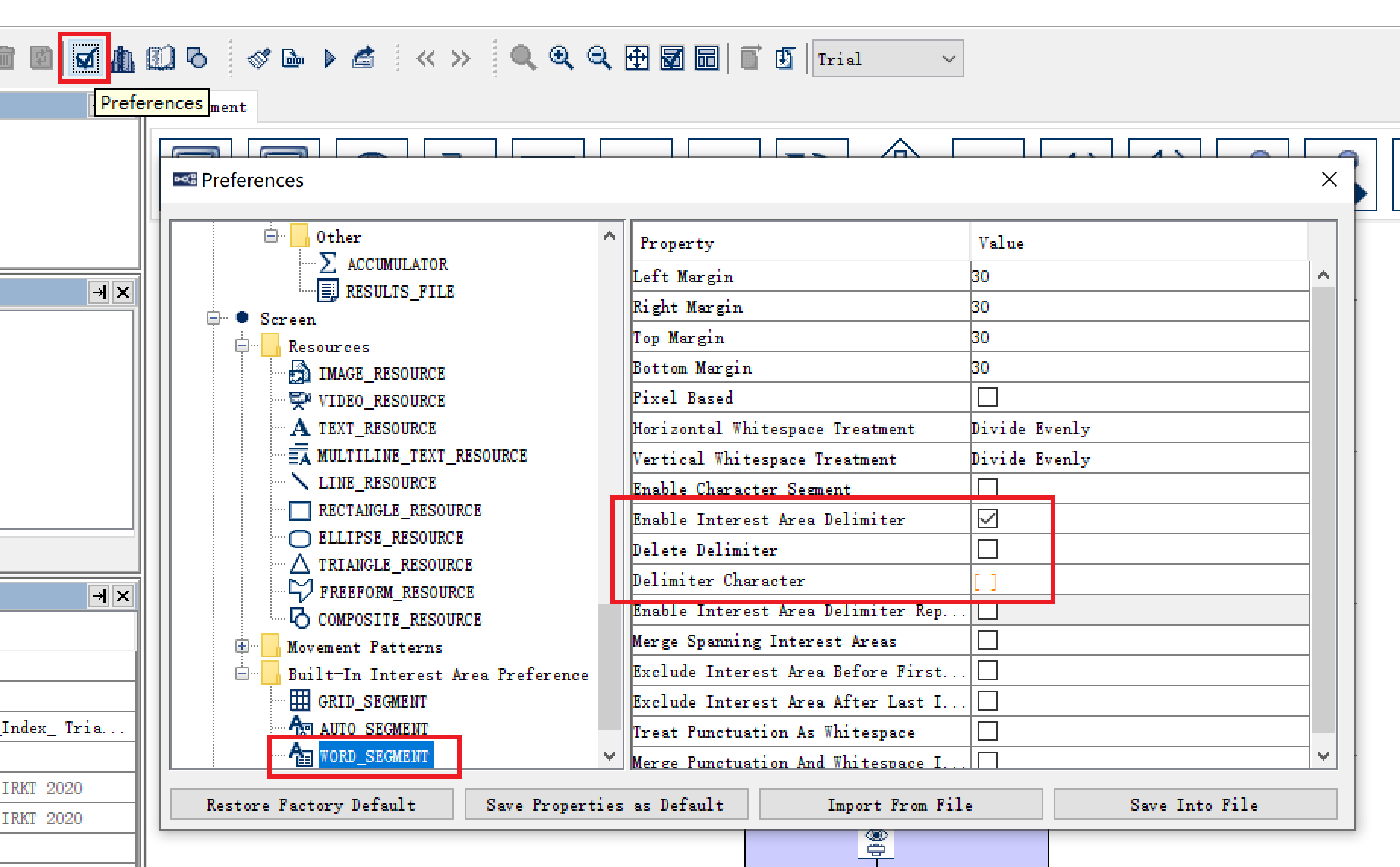
在此步设置中,我们需要执行三处设置:
- 将
Enable Interest Area Delimiter设置为True,开启分词功能; - 将
Delete Delimiter设置为Flase,设置不隐藏分词符; - 将
Delimiter Character设置为“ ”,即空格。
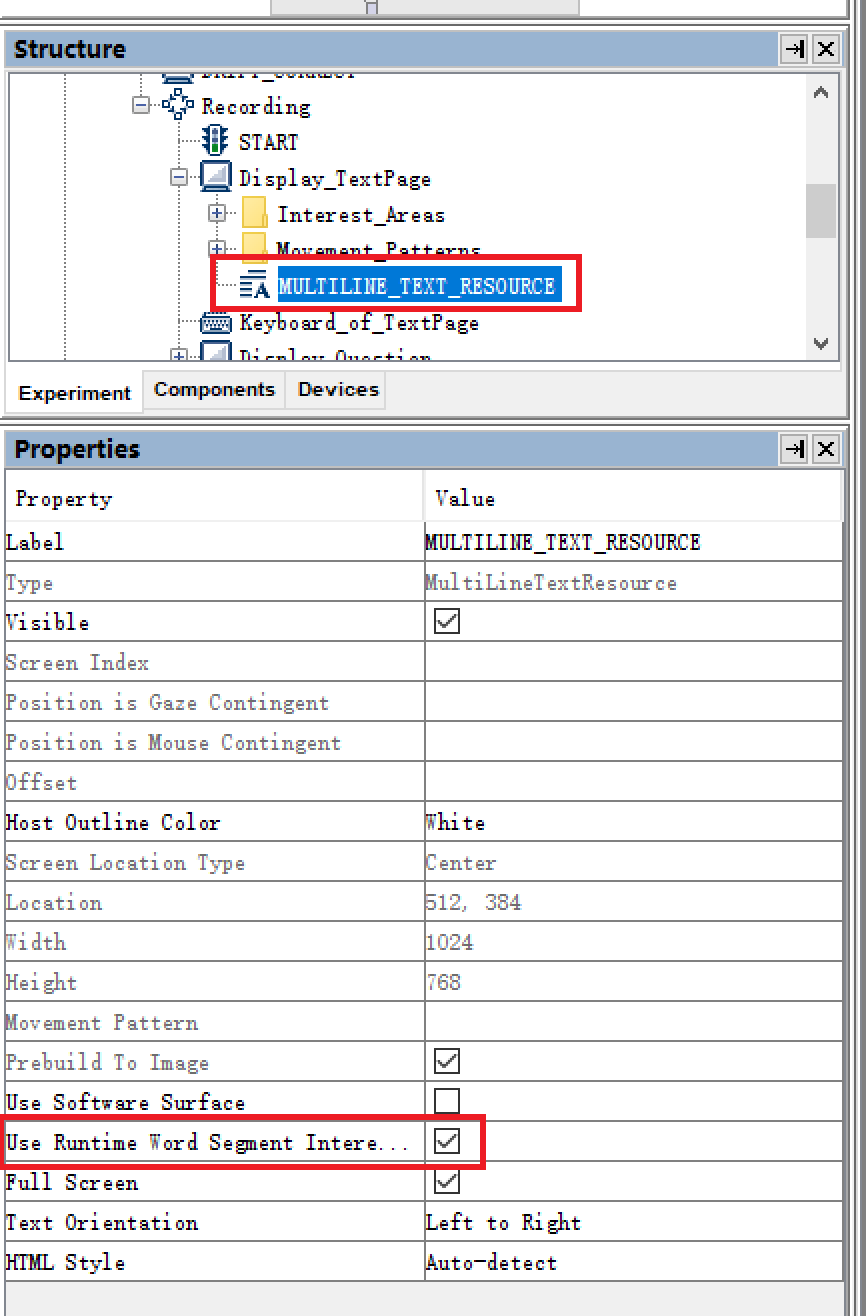
Step 2: 对特定的TextSource进行Auto Word Segment
回到呈现文本刺激的Display控件中,选中承载Datasource中文本内容的MULTILINE_TEXT_RESOURCE,将其Use Runtime Word Segment InterestArea设置为True。
非分词文字 - 中文、日文、藏文等
此类文字的特点是词与词之间没有天然的空格分割。
Step 1: 开启Auto Word Segment功能
在工具栏中点击Preference,在左侧的树状结构中依次点击“Preference - Screen - Built-in Interest Area Preference - Word Segment”,找到Word Segment。
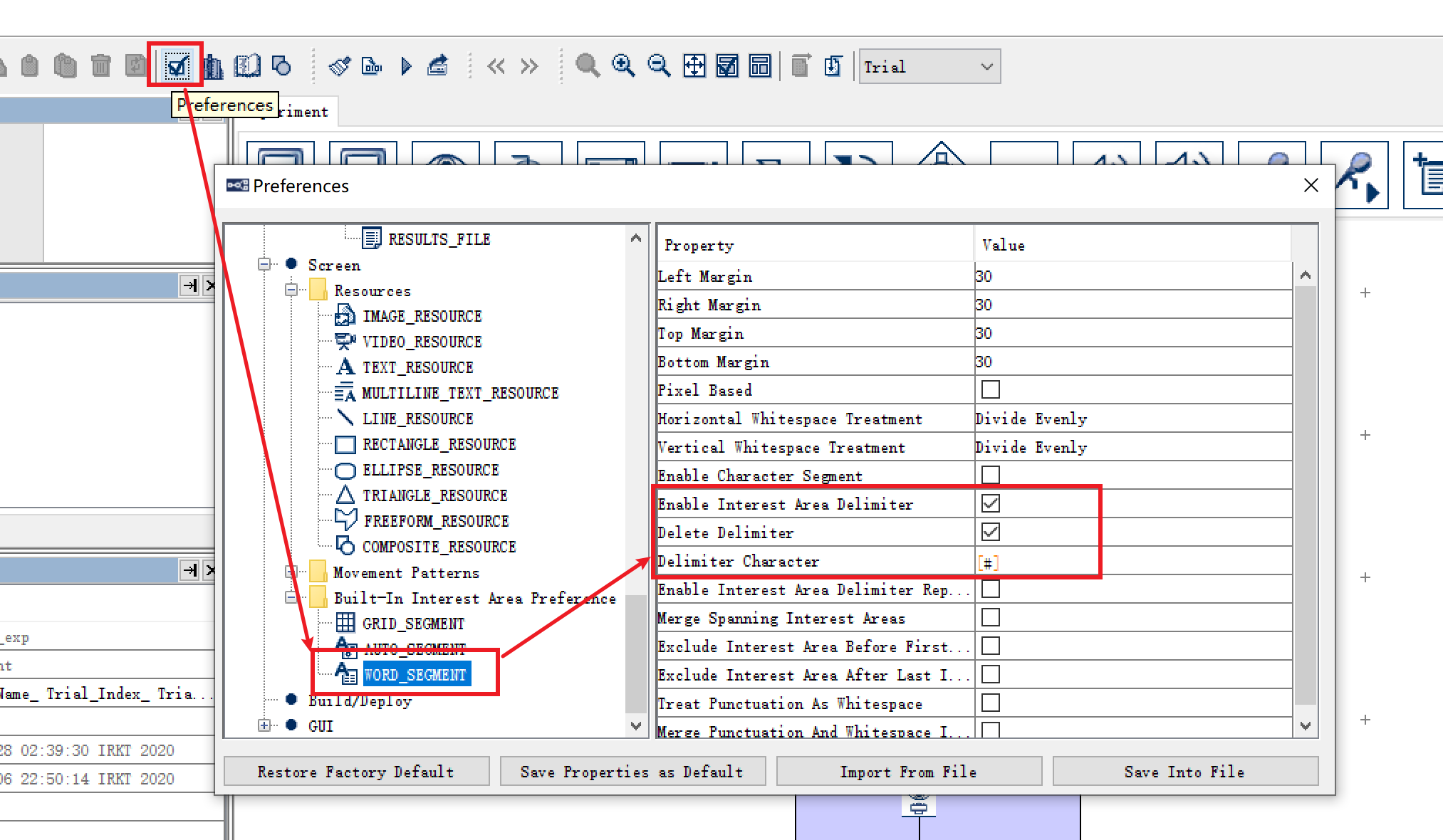
在此步设置中,我们需要执行三处设置:
- 将
Enable Interest Area Delimiter设置为True,此步开启分词功能; - 将
Delete Delimiter设置为True,此步设置隐藏分词符; - 将
Delimiter Character设置为我们制定的字符“#”。
Step 2: 修改DataSource
向我们的文字中加入分词符“#”,重新写入DataSource中。

Step 3: 对特定的TextSource进行Auto Word Segment
回到呈现文本刺激的Display控件中,选中承载Datasource中文本内容的MULTILINE_TEXT_RESOURCE,将其Use Runtime Word Segment InterestArea设置为True。
Test Run一下试试吧!
以上。